Hardware GPGPU
Thead and Group¶
在 GPU 编程的过程中,根据程序具体的执行需求,可将 线程 划分为由 线程组(thread group) 构成 的网格(grid)。
numthread 和 Dispatch 的三维 Grid 的设置方式只是方便逻辑上的划分,硬件执行的时候还会把所有线程当成一维的。因此 numthread(8, 8, 1) 和 numthread(64, 1, 1) 只是对我们来说索引线程的方式不一样而已,除外没区别。
具体划分见 Compute Shader in Unity#Thread and Group
Thread and Group in Hardware¶
GPU 会有上千个“核心”,用 NVIDIA 的说法就是 CUDA Core。
SP:最基本的处理单元,streaming processor,也称为 CUDA core。最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理。常说的几百核心的 GPU 值指的都是 SP 的数量。
SM:多个 SP 加上其他的一些资源组成一个 streaming multiprocessor。也叫 GPU 大核,其他资源如:warp scheduler,register,shared memory 等。SM 可以看做 GPU 的心脏,register 和 shared memory 是 SM 的稀缺资源。CUDA 将这些资源分配给所有驻留在 SM 中的 threads。因此,这些有限的资源就使每个 SM 中 active warps 有非常严格的限制,也就限制了并行能力。
这些核心被组织在流式多处理器(streaming multiprocessor, SM)中,一个线程组运行于一个多处理器(SM)之上。每一个 SP 同一时间可以运行一个线程。
Warp and Wavefront¶
SM 会将它从 Gigathread 引擎(NVIDIA 技术,专门管理整个流水线)那收到的大线程块,拆分成许多更小的堆,每个堆包含 32 个线程,这样的堆也被称为:warp (AMD 则称为 wavefront)。多处理器会以 SIMD32 的方式(即 32 个线程同时执行相同的指令序列)来处理 warp,每个 CUDA 核心都可处理一个线程。
每一个线程组都会被划分到一个 Compute Unit 来计算,线程组中的线程由 Compute Unit 中的 SIMD 部分来执行。
如果我们定义 numthreads(8, 2, 4) ,那么每个线程组就有 \(8×2×4=64\) 个线程,这一整个线程组会被分成两个 warp,调度到单个 SIMD 单元计算。
单个 SM 处理逐个 warp,当一个 warp 暂时需要等待数据的时候,就可以先换其他 warp 继续执行。
Set Size of Thread Group¶
应当总是将线程组的大小设置为 warp 尺寸的整数倍。让 SM 同时容纳多个 warp,能够以防一些情况。
例如有时候为了等待某些数据就绪,不得不停下来。比如说,我们需要通过法线纹理贴图来计算法线光照,即使该法线纹理已经在 Cache 中了,访问该资源仍然会有所耗时,而如果它不在 Cache 中,那就更加耗时了。用专业术语讲就是 Memory Stall(内存延迟)。与其什么事情也不做,不如将当前的 Warp 换成其它已经准备就绪的 Warp 继续执行。
NVIDIA 公司生产的图形硬件所用的 warp 单位共有 32 个线程。而 ATI 公司采用的 “wavefront” 单位则具有 64 个线程,且建议为其分配的线程组大小应总为 wavefront 尺寸的整数倍。另外,值得一提的是,不管是 warp 还是 wavefront,它们的大小在未来几代中都有可能发生改变。
总之,每个 SM 的操作度是 warp,但是每个 SM 可以同时处理多个 warp。然后因为有内存等待(memory stall)的问题,同一个 thread block 有可能需要等待内存才做,因此可以使用多个线程组交叉运行。warp 对我们是不可见和不可编程的,我们可编程的只有线程组。
Communication between Thread¶
Communication between Multi Thread Groups¶
thread 不能访问其他 group 的共享内存。
group 之间的通信需要 L2 Cache 支持。L2 Cache 性能有所折扣, 因此要见着 group 间的通信。
Communication in Single Thread Group¶
单个 group 之间的 thread 的通信, 通过 Local Data Share (LSD)来完成。LDS 的速度是快于 L1 Cache 的。
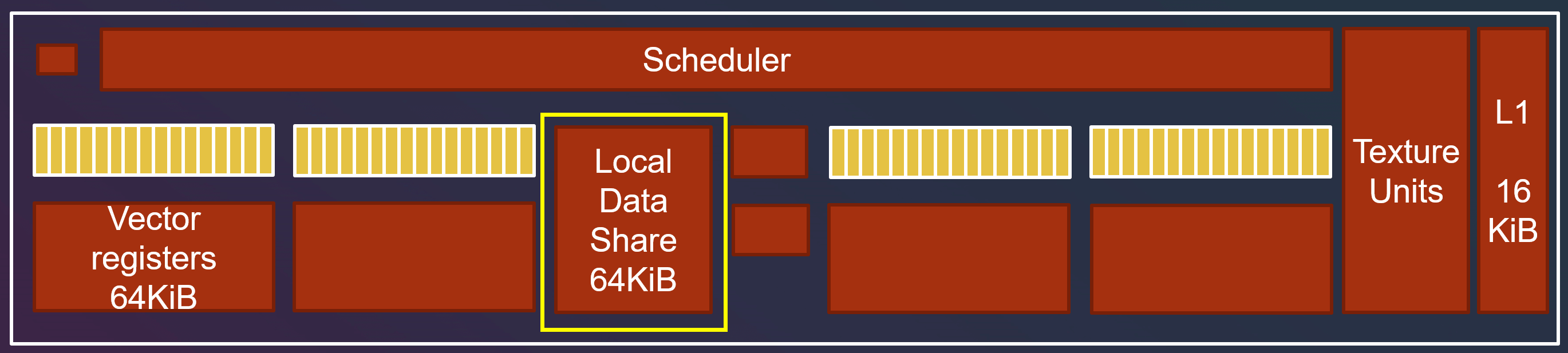
LDS 会被某些着色阶段使用, 如 fragment shader (pixel shader) 需要用 LDS 来进行插值。但 Compute Shader 和传统着色器不同, 不需要 LDS, 故可以随意只用 LDS。
groupshared float data[8][8];
[numthreads(8,8,1)]
void main(ivec3 index : SV_GroupThreadID)
{
data[index.x][index.y] = 0.0;
GroupMemoryBarrierWithGroupSync();
data[index.y][index.x] += index.x;
…
}
需要组内共享的变量加上 groupshared , 同时为了保证其他线程正确读取到数据, 需要通过 Barrier 来保证读的时候 LDS 有需要的数据。
Vector Register and Scalar Register¶
如果有些变量是线程独立的,称之为 “non-uniform” 变量。(如果一个线程组内有 64 个线程,就要存 64 份数据)
如果有些变量是线程间共享的,称之为 “uniform” 变量,例如线程组 id 是组内每个线程都一样的。(每个线程组内只存 1 份数据)
“non-uniform” 变量会被储存到 Vector Register(VGPR, vector general purpose register)中。
“uniform” 变量会被储存到 Scalar Register(SGPR, scalar general purpose register)中。
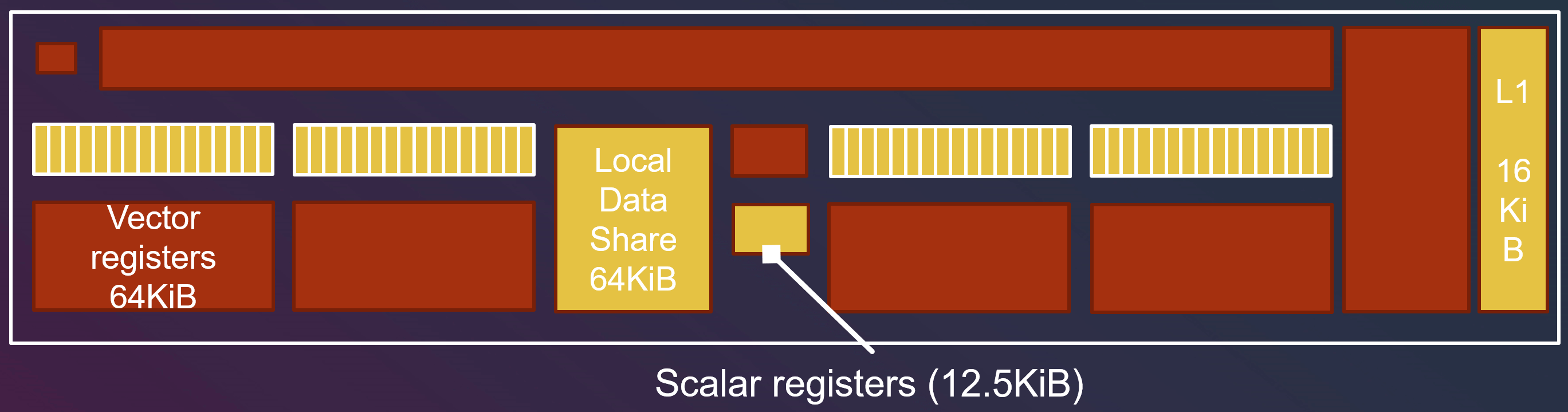
如果用了过多 “non-uniform” 变量导致 Vector Register 装不下,就会导致分配给 SIMD 的线程组数量降低。
Differences with Traditional Shader Execution Pipeline¶
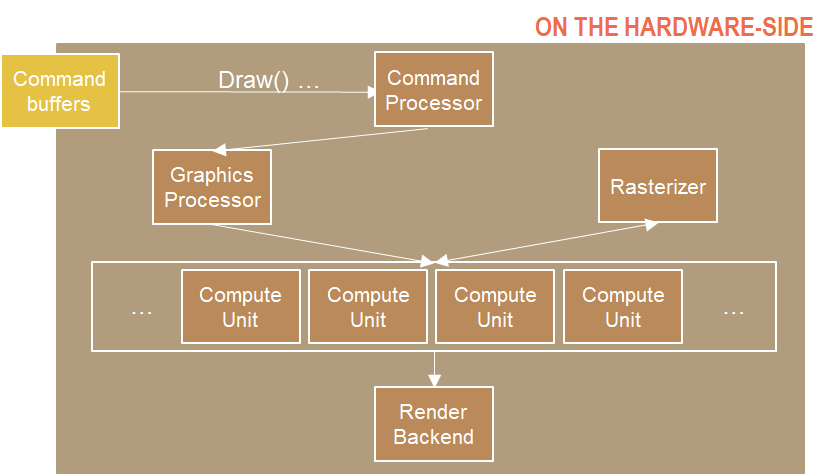
Vert-Frag Shader:
Command Processor 收集并处理所有命令,发送到 GPU。
Draw() 命令发送后,Command Processor 告知 Graphics Processor 要做的事情。
顶点着色器和其他需要计算的阶段被送到 Compute Unit 去计算,处理完会到 Rasterizer (光栅器),并返回处理好的像素到 Compute Unit 执行像素着色(Pixel shader)。
输出到 RenderTarget。
Compute Shader:
Command Processor 仍会收集并处理所有命令,发送到 GPU。
不需要传数据到 Graphics Processor, 而是直接传到 Compute Unit。
Compute Unit 开始处理 Compute Shader,输入可以有 constants 和 resources(对应 DirectX 的 Resource 可以绑定到渲染管线的资源,例如顶点数组等),输出可以有 writable resources(UAV, Unordered Access View 能被着色器写入的资源视图)。
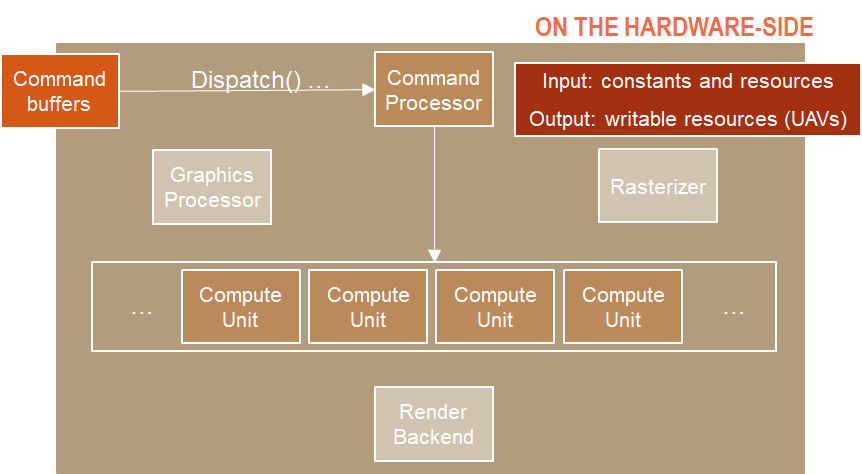
因此,如果我们用了 Compute Shader,可以不通过渲染管线,跳过 Render Output,使用更少硬件资源,利用 GPU 来完成一些渲染不相关的工作。此外,Compute Shader 的流水线**需要的信息也更少**。

Disadvantages¶
难以 Debug。
至少需要 DX11 和 OpenGL ES3。
不同平台针对错误的处理不一致。
数组越界:dx 返回0, 其他平台出错。
变量和关键字或内置函数重名:dx 无影响, 其他平台出错。
SBuffer 和内存布局不一致:dx 会自动转换, 其他平台会出错。
Buffer 未初始化:dx 全是0, 但其他平台可能是任意值或 NaN。
Application¶
Unity线上技术大会-游戏专场|从手机走向主机 -《原神》主机版渲染技术分享
《天涯明月刀》手游引擎技术负责人:如何应用GPU Driven优化渲染效果?| TGDC 2020
三七研发,这款被称作 “目前最原汁原味的”《斗罗大陆》3D 手游都用到了哪些 Unity 技术?
DD2018: Sebastian Aaltonen - GPU based clay simulation and ray tracing tech in Claybook